In case you feel the urge to get to know more about this project, I really encourage you to contact me directly.


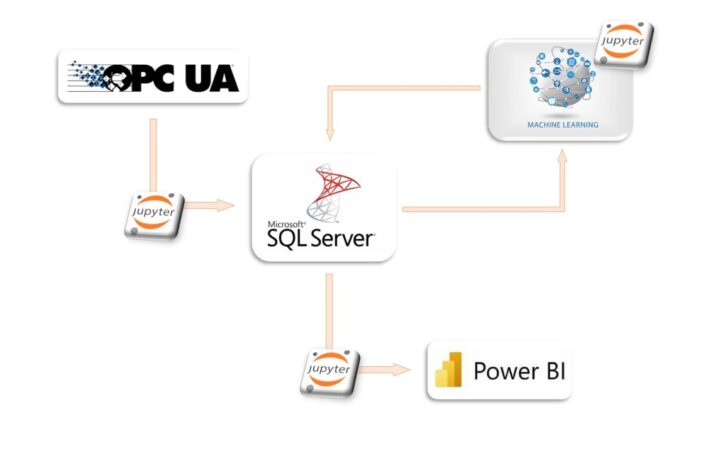
OPC UA SERVER
Production data repository, which functions as a database. This allows for easy extraction of historical data to process according to our needs, making it a perfect data source.

JUPYTER
Programming environment where we will train and deploy our AI forecaster. Python will be used as the main programming language for machine learning purposes.

SQL SERVER
Programming environment where we will train and deploy our AI forecaster. Python will be used as the main programming language for machine learning purposes.

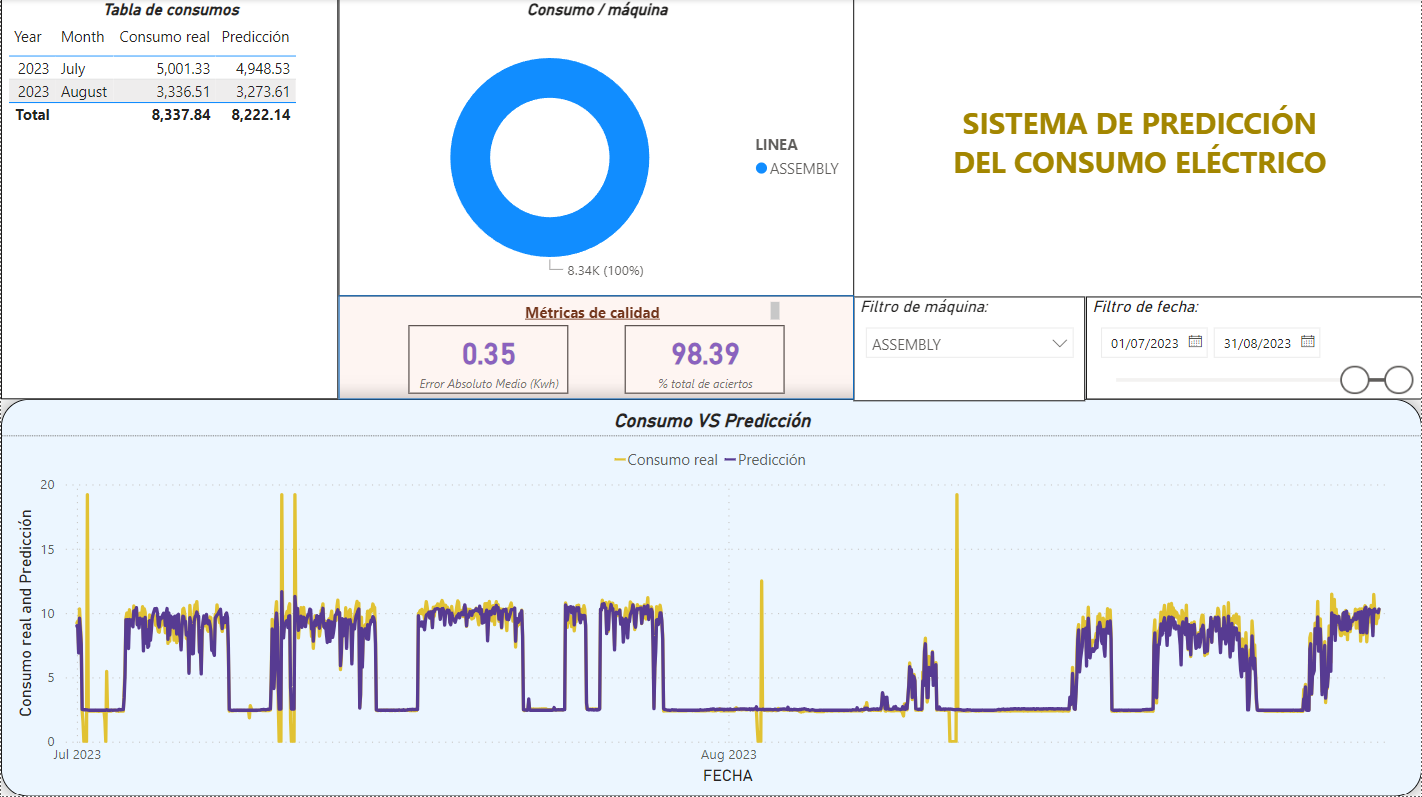
POWER BI
Data visualizer tool which will help us connect the world of big data with the daily company activities, making every step achieved visible to everyone at any moment.
However, it is not the purpose of this post to get into it.

Big J Insights
This is a brief introduction to my AI project. I hope you find it inspiring and can´t wait for you to start your own!

